




The construction industry, long known for its hands-on processes and fragmented workflows, is undergoing a digital revolution. This transformation has involved the adoption of cutting-edge digital technologies such as building information modelling (BIM), robotics, automation, the Internet of Things, digital twins and, today, artificial intelligence (AI).
The new generation of generative AI can have a significant impact on reshaping how we design, build and manage projects, enhancing productivity, efficiency and sustainability.
Table 1 categorises the key generative AI applications across construction education, training and professional practice, showcasing how these tools enhance theoretical learning, practical skills development and operational efficiency. The applications range from personalised instruction and immersive simulations to automated compliance and AI-driven design innovation, reflecting the transformative and interdisciplinary potential of generative AI in the built environment.

What are generative AI and large language models (LLMs)?
Generative AI is a type of artificial intelligence that can create new content such as text, images, designs or code by learning patterns from existing data.
At the heart of many generative AI tools are large language models (LLMs). These are advanced AI systems trained on massive amounts of text. They understand how language works and can produce human-like writing.
Generative AI’s personalised learning
Generative AI, especially large language models (LLMs) like ChatGPT, Gemini and Claude, are among the most talked-about advancements. Already making waves in sectors like education, healthcare and finance, these tools can write documents, analyse data and support communication across language – capabilities that are highly relevant for construction. In education, generative AI is opening doors for personalised learning, helping students and professionals strengthen their skills in areas like construction management and engineering.
Adoption in the construction industry, however, still faces roadblocks. Industry-specific models are still not that common, data is often unstructured and there are legal and regulatory grey areas. Generative AI might suggest architectural concepts, but it struggles to factor in structural or material constraints without manual adjustments.
Similarly, AI-generated schedules often miss the mark when it comes to project-specific disruptions. To close that gap, we need tailored AI tools, clearer regulations and education that prepares professionals to use these technologies effectively in real-world settings, particularly to restrain the risk of hallucination (when information sounds plausible but is factually incorrect, misleading or entirely made up).
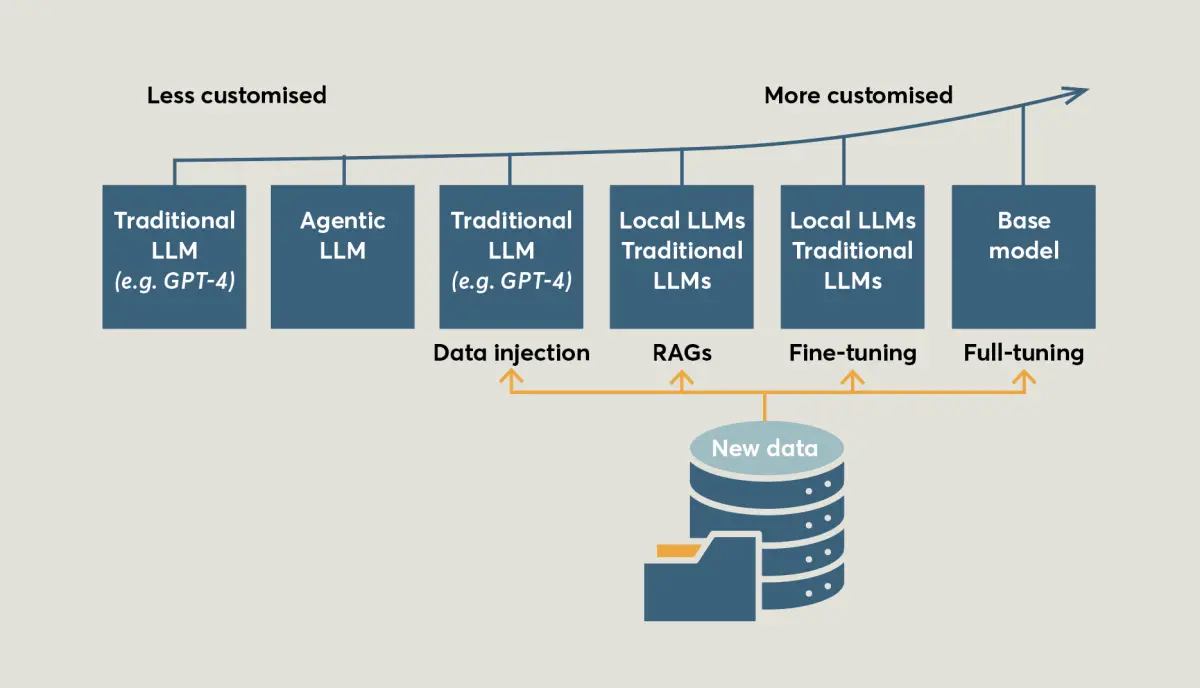
Today, there are several ways to adapt LLMs like GPT-4 for use in construction. Figure 1 shows a range of options – from using ready-made AI tools to more hands-on customised set-ups. If you use an LLM straight out of the box, it’s great at general tasks but won’t know anything about your specific construction project. That’s where customisation comes in – helping the model understand and respond to industry-specific needs.
Consequently, it will do its best to answer prompts with the knowledge embedded in it when it was created and is prone to severe hallucinations. Existing LLMs can act without human intervention (called agentic LLMs), for example, to reply to emails or serve as the backbone of an AI chatbot.
The limits with injecting data
Hallucination problems can now be mitigated by customising existing LLMs. The simplest way is data injection – hand over a stack of plans or safety notes every time you ask a question so the answers stay on-topic without changing the LLM’s long-term memory.
This solution has several limitations in terms of how much text can be injected and the quality of the documents due to the context length that an LLM can operate with. Injecting unstructured PDF files is the worst approach for data injection. LLMs are machines and need to be fed with data that is easier to interpret. Data parsing means breaking information into smaller, clearer parts so a computer can understand it. This step is key to making sure the data keeps its meaning – something that’s crucial for getting accurate results from AI tools like LLMs.
Handling large amounts of data
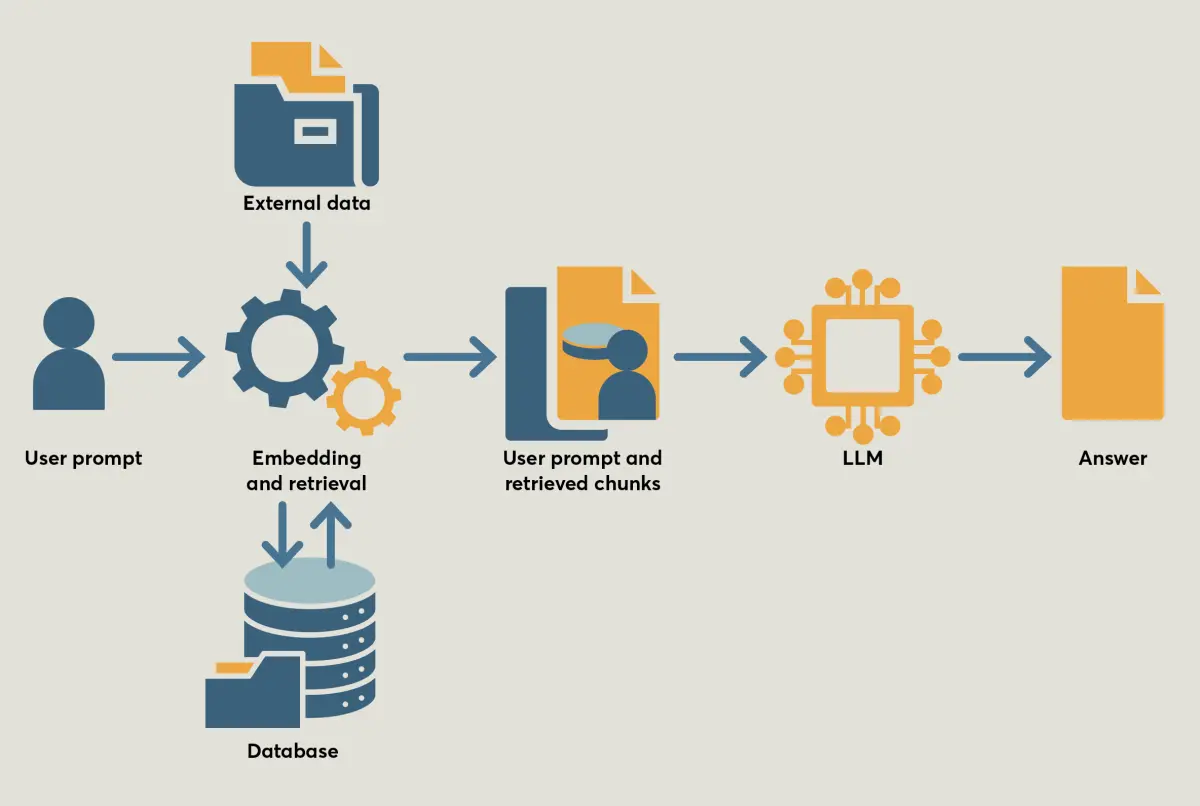
One effective solution to handling a large amount of data is retrieval-augmented generation (RAG), which enhances LLM performance by dynamically incorporating information from an external knowledge base (see Figure 2). It breaks down source documents into smaller, manageable chunks. Each chunk is then turned into a set of numbers that captures its meaning and stored in a vector database – a special type designed for handling this kind of data.
When a user submits a query, the system performs a semantic search on this database to retrieve the most relevant chunks of information. These are then combined with the original query and fed into the LLM’s context window. While the total volume of data stored in the RAG system can be vast, the primary operational constraint is the size of the LLM’s context window, which limits how many retrieved chunks can be processed for any single response.
Go further, and we can start fine-tuning existing LLMs – for example, putting the LLM through a quick course based on past site reports so the new knowledge is baked in. This solution can generate answers more quickly – there is no time spent retrieving data from an external database – but it requires major work in structuring the data in a format usable for fine-tuning and hardware resources to accomplish the tuning.
At the other extreme, an investment can be made in full-tuning – training a bespoke LLM that learns a company’s entire way of working from the ground up. Each rung on this ladder gives you a model that speaks your language more fluently – but it also takes more time, money and technical know-how to get there. As this requires very high development costs, it is only affordable for a few big global IT corporations at present.
Securing your data
What about data privacy? Using a cloud-hosted AI like GPT-4 is a bit like hiring an off-site consultant. You ask questions to its secure servers, and it gives fast, high-quality answers. However, you must trust its promise not to keep or share your drawings, contracts or site photos.
Running an open-source model – a local LLM – on your own computer flips the script. Nothing ever leaves your network, so now you are in full control of privacy and compliance, yet you need the hardware, IT skills and time to keep that model updated.
The practical rule for construction is
simple – routine queries or public information can safely go to the cloud, while anything sensitive such as tender bids, HR files and proprietary BIM data is best handled on an enterprise no-logging plan or a local model locked behind a firewall.
Construction’s data-driven future?
Generative AI is edging construction towards a data-driven future, but turning hype into productivity means starting small.
Yet key obstacles remain. AI-generated schedules miss real-world disruptions, design tools ignore structural and material limits, legal frameworks lag and industry data is fragmented and messy – risks compounded if education relies on AI at the expense of hands-on skills.
Massey University’s School of Built Environment is tackling these gaps by weaving AI into its curriculum, advancing simulation-based and adaptive training, and aligning research with Construction 4.0 and Te Ara Paerangi Future Pathways priorities to prepare a workforce ready to translate tomorrow’s smart algorithms into tangible building-site gains.